【JPA】批量操作数据时耗时长的问题解决方案 |
您所在的位置:网站首页 › jpa 批量删除 › 【JPA】批量操作数据时耗时长的问题解决方案 |
【JPA】批量操作数据时耗时长的问题解决方案
|
这里写自定义目录标题
出现的场景确认原因具体问题排查和源码排查解决方法结语
出现的场景
在SpringBoot新项目的开发中,项目使用了JPA规范+Hibernate的实现方式来做持久层映射,开发速度提高了不少,在随后的深度开发中,项目中涉及到了越来越多的批量操作数据的问题,而简单的使用JPA提供的saveAll()方法,据开发反馈一次批量操作5000条数据竟然耗时了30S+,按理说是不太可能的,那么再不更换持久层的前提下,如何优化这个方式呢? 确认原因我们在进行一次简单的单元测试来复现这个问题,建一张表来进行简单的批量操作,然后单元测试进行大批量操作,可以确定在进行1000条数据的update或者insert的时候,已经达到了耗时17S的严重问题,但是本身JPA并没有这方面的BUG。 首先确认是否是数据库所在服务器的问题,更欢数据库服务器连接之后,仍然存在问题,说明服务器并没有限制连接的问题。在使用JPA的日志反馈功能,在SpringBoot的配置文件中YML或者properties文件中,增加spring.jpa.properties.hibernate.generate_statistics=true,该命令是hibernate的一个调优指令,可以将Session级别的各个指令相关信息打印出来,如: 2022-06-30 17:23:35.740 INFO 11088 --- [ main] i.StatisticalLoggingSessionEventListener : Session Metrics { 14300 nanoseconds spent acquiring 1 JDBC connections; 0 nanoseconds spent releasing 0 JDBC connections; 230700 nanoseconds spent preparing 1 JDBC statements; 214581201 nanoseconds spent executing 10 JDBC statements; 0 nanoseconds spent executing 0 JDBC batches; 0 nanoseconds spent performing 0 L2C puts; 0 nanoseconds spent performing 0 L2C hits; 0 nanoseconds spent performing 0 L2C misses; 2806052600 nanoseconds spent executing 1 flushes (flushing a total of 80000 entities and 0 collections); 0 nanoseconds spent executing 0 partial-flushes (flushing a total of 0 entities and 0 collections) }上面的日志记录的保存10条信息所耗时的纳秒,准备的纳秒等等,可以看到 JDBC batches是没有执行的,即使你是用了JPA的saveAll()方法,此时就确定了JPA的问题 具体问题排查和源码排查我们在确定了JPA并没有执行batch问题之后,首先要知道,在根据上图的日志记录,我们发现10条数据并不是一次性写入了数据库的,而是一条一条insert到数据库的,这严重影响了数据库的性能,但是你如果在Navicat中写10insert语句,他也不会有这么严重的耗时,这时,我们就进入saveAll方法判断,究竟是哪里产生了大的耗时如图 在这个方法中JPA需要进行一系列操作去判断你传进来的这个entity对象是需要保存还是更新,所以才会有长时间保存,相当于我save一个对象,这个对象首先会被Hibernate进行托管,然后进行保存校验,接着构建响应的SQL语句,最后执行,这一系列操作其实完全在重复运行。如果Hibernate的二级缓存启用,将构建Sql语句和执行拆开,即构建完所有的Sql语句,那么他会耗时很少。 解决方法说到底,上边我们只是知道了JPA的save执行的大致过程,我们仍需要解决这个问题,而问题在于开启批量操作。那么问题就很容易解决了 首先我们新增配置信息,在application.yml或者application.properties文件中新增 spring: jpa: properties: hibernate: jdbc: batch_size: 2000 #开启批次储存,一批次储存量为2000,如有10000条数据则储存五次 order_inserts: true order_update: true完事,我们做一次校验,查看是否有效,我们在单元测试中批量写入90000条数据,日志显示: 2022-06-30 17:23:35.740 INFO 11088 --- [ main] i.StatisticalLoggingSessionEventListener : Session Metrics { 14300 nanoseconds spent acquiring 1 JDBC connections; 0 nanoseconds spent releasing 0 JDBC connections; 230700 nanoseconds spent preparing 1 JDBC statements; 0 nanoseconds spent executing 0 JDBC statements; 2349585500 nanoseconds spent executing 40 JDBC batches; 0 nanoseconds spent performing 0 L2C puts; 0 nanoseconds spent performing 0 L2C hits; 0 nanoseconds spent performing 0 L2C misses; 2806052600 nanoseconds spent executing 1 flushes (flushing a total of 80000 entities and 0 collections); 0 nanoseconds spent executing 0 partial-flushes (flushing a total of 0 entities and 0 collections) } 2022-06-30 17:23:35.750 INFO 11088 --- [ main] c.example.jpa.service.UserDetailService : 保存userDetail:80000条数据,共计耗时:3244ms 2022-06-30 17:23:35.750 INFO 11088 --- [ main] com.example.jpa.service.TestUserService : 业务执行了4022ms,共计执行了90000条数据 结语最后发现90000条数据才耗时4s,虽然还有优化的地方,但目前为止已经可以解决开发中的问题了。 |
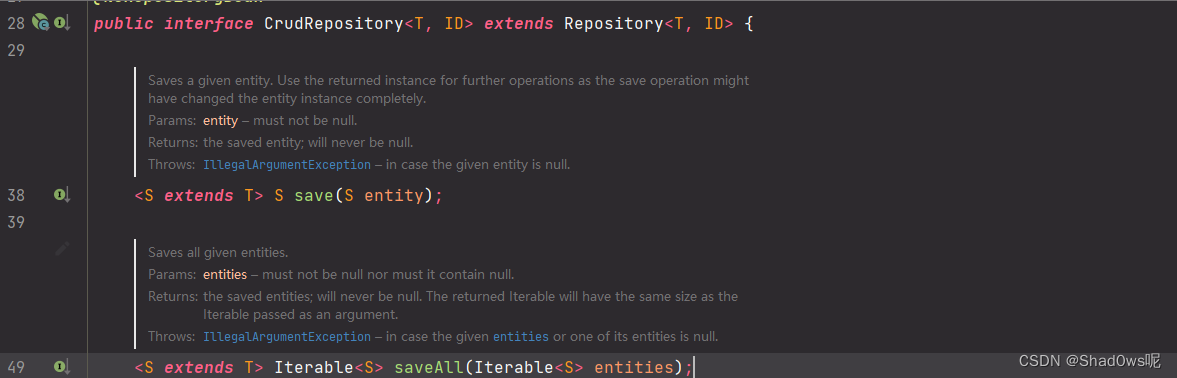 我们去看看具体的实现,在JPA+Hibernate的构成中,在没有指定或新增的情况下,默认的实现类是:
我们去看看具体的实现,在JPA+Hibernate的构成中,在没有指定或新增的情况下,默认的实现类是:  SimpleJpaRepository方法
SimpleJpaRepository方法 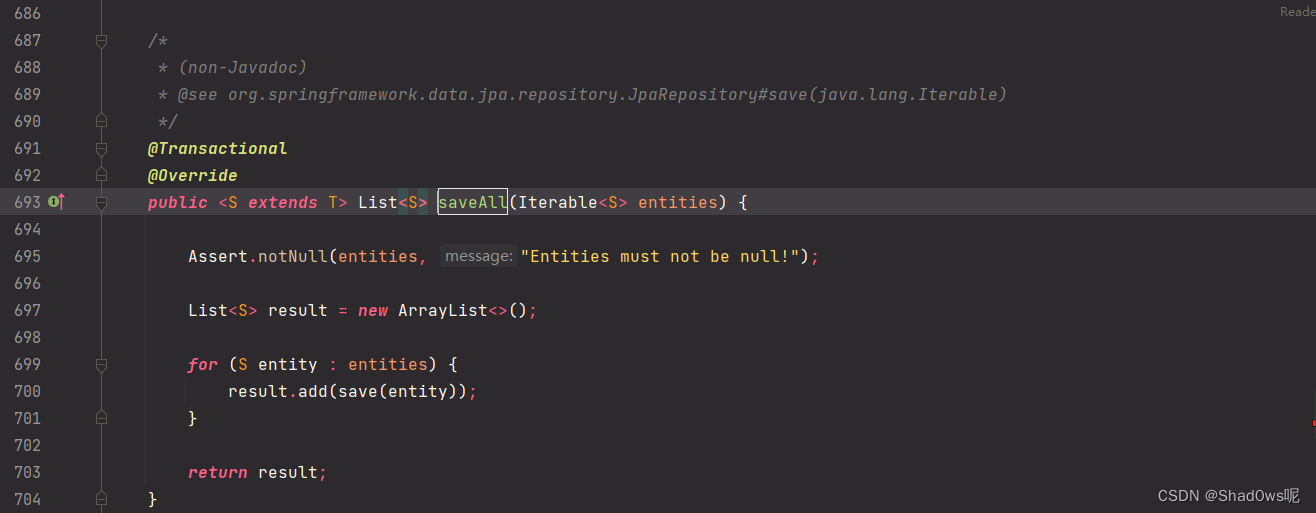 这里我们发现,其实saveAll()就是循环去执行了save方法,那我们看看save方法
这里我们发现,其实saveAll()就是循环去执行了save方法,那我们看看save方法 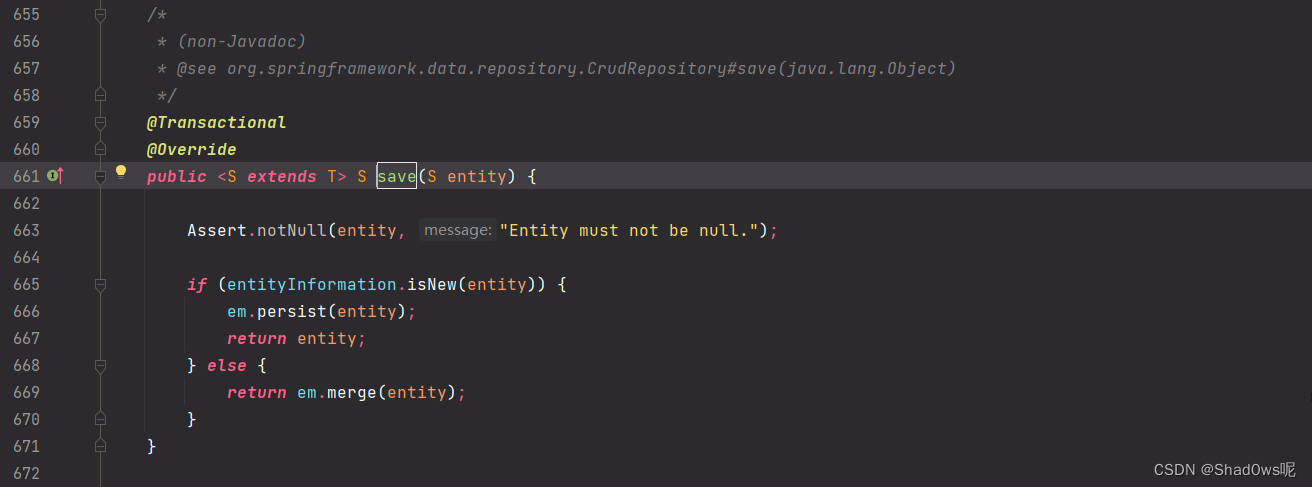 这里我们调测可以发现,其实save方法最耗时的方法是
这里我们调测可以发现,其实save方法最耗时的方法是【本文地址】
今日新闻 |
推荐新闻 |